FastAPI Development Services: Build Lightning-Fast, Scalable APIs with Python
FastAPI development services help startups and enterprises build lightning-fast, scalable, and secure Python APIs that power modern SaaS, AI, and microservice platforms. At Zestminds, our FastAPI experts design production-ready backends with async performance, DevOps automation, and measurable ROI. Discover why FastAPI outperforms Flask and Django for teams that demand speed, reliability, and growth-ready architecture.


The TL;DR for Busy Founders
FastAPI delivers near-Go performance with Python simplicity. Zestminds turns that power into outcomes: optimized endpoints, async architecture, and cloud-ready deployments that often cut infrastructure spend by up to 40 percent.
Why FastAPI Is the Future of Python Backend Development
Frameworks like Flask and Django once dominated the Python world, but they struggle with concurrency and heavy traffic. FastAPI was built to fix that. Using Starlette for networking and Pydantic for data validation, it achieves speeds close to Node.js or Go while staying completely Pythonic.
- Blazing performance: Benchmarked among top Python frameworks by TechEmpower.
- Developer happiness: Type hints, automatic docs, and built-in validation make code cleaner and safer.
- Async-native: Handles thousands of concurrent requests with non-blocking I/O.
- Cloud-ready: Works perfectly with Uvicorn, Gunicorn, Docker, and modern CI/CD systems.
One Berlin-based SaaS startup switched from Flask to FastAPI with our help and saw response times drop from 950 ms to 210 ms while reducing AWS cost by 35 percent. That’s the tangible power of async engineering.
Key Benefits of Choosing FastAPI for Startups and Enterprises
1. Speed That Grows With You
FastAPI thrives under load. Its async engine processes multiple requests at once without spawning threads. A single FastAPI node can handle 1,000 RPS where Flask would need three or more servers.
For a logistics client, Zestminds rebuilt the live-tracking backend in FastAPI and achieved a 68 percent latency reduction before adding new hardware.
2. Type Safety and Validation by Design
Pydantic models eliminate mismatched payloads:
from pydantic import BaseModel
class Order(BaseModel):
id: int
item: str
price: float
Validation happens automatically, and OpenAPI docs generate instantly—saving QA and PM teams countless hours.
3. Security That’s Enterprise-Grade
API security is built into FastAPI through OAuth2, JWT, and dependency injection. At Zestminds we extend this with token rotation, rate limiting, and environment-level encryption to meet SOC 2 and GDPR standards. For healthcare or fintech use cases, review our HIPAA-compliant AI hospital system project.
4. Perfect for AI, SaaS, and Microservices
FastAPI integrates beautifully with AI and ML models, Celery queues, and microservice architectures. For example:
@app.post("/predict/")
async def predict(data: InputData):
result = await model.predict(data.text)
return {"prediction": result}
This pattern powers real-time inference in projects like our AI workflows with FastAPI and LangGraph and AI kitchen planner using OpenAI + Weaviate + FastAPI.
5. Faster MVPs, Lower Costs
Because FastAPI auto-generates documentation and reduces boilerplate, development time shrinks by 30–50 percent. For early-stage startups, that means investor demos in weeks, not months.
FastAPI vs Flask vs Django: Choosing Your Stack
Every CTO faces the same question—Flask, Django, or FastAPI?
- FastAPI: Best for APIs, SaaS, AI services. Fully async, auto-docs, highest performance.
- Flask: Great for prototypes but limited scalability.
- Django: Excellent for CMS or admin-heavy platforms.
FastAPI vs Flask vs Django
Quick visual comparison of performance, scalability, documentation, async support, and use cases.
| Feature | FastAPI | Flask | Django |
|---|---|---|---|
| Speed | |||
| Scalability | High (Async + Lightweight) | Moderate | Moderate–High |
| Documentation | Auto-generated (OpenAPI) | Manual | Built-in |
| Async Support | Native Async I/O | Limited (via plugins) | Partial (3.1+) |
| Ideal Use Case | APIs, SaaS, AI, Microservices | Prototypes, MVPs | CMS, Full-Stack Web Apps |
Benchmarked by TechEmpower 2025, FastAPI leads Python frameworks in performance and async capability.
Verdict: If your business revolves around APIs, choose FastAPI from day one. It’s the scalable choice that saves re-architecture pain later.
Field Example
A California fintech using Flask for credit-risk scoring faced 900 ms latency. After migrating to FastAPI with Redis caching and async workers, latency fell to 220 ms, uptime rose to 99.98 percent, and infrastructure cost dropped 38 percent. That’s ROI you can measure.
Our FastAPI Development Services at Zestminds
FastAPI delivers its best results only when paired with strong architecture and DevOps discipline. Here’s how we help founders succeed.
1. FastAPI Consulting and Architecture Design
We define the right architecture—monolith, modular, or microservice—set latency goals, and design observability from day one. Using Grafana dashboards and OpenAPI specs, clients see exactly how requests flow before coding begins.
2. Custom API Development
Our engineers craft REST and GraphQL APIs with async I/O, pagination, exception handling, and automated testing. Multi-tenant SaaS? Multi-region APIs? Done and proven.
3. AI and ML Integration
We connect FastAPI with TensorFlow, PyTorch, and LangChain to serve LLMs or prediction models. One recruitment platform cut match-time latency from 1.2 s to 300 ms. See similar impact in our AI automation case study.
4. DevOps, CI/CD, and Cloud Deployment
Zestminds engineers build zero-downtime pipelines using Docker, Kubernetes, and Uvicorn/Gunicorn workers behind NGINX. CI/CD via GitHub Actions or Jenkins pushes straight to AWS ECS, GCP Cloud Run, or Azure AKS with automated monitoring.
5. Maintenance and Scaling
Post-launch, we handle versioning, load testing, and auto-scaling. That’s why many clients keep us on retainer—because scaling safely is harder than launching fast.
FastAPI in Production: From Local Build to Global Scale
Every Zestminds FastAPI project follows a predictable deployment lifecycle built for reliability.
- Runtime: FastAPI + Uvicorn + Gunicorn
- Proxy: NGINX with caching and rate limiting
- Containers: Multi-stage Docker builds
- Orchestration: Kubernetes / EKS / GKE / AKS
- Monitoring: Prometheus, Grafana, ELK
This consistency ensures performance metrics stay stable even under investor-day traffic spikes.
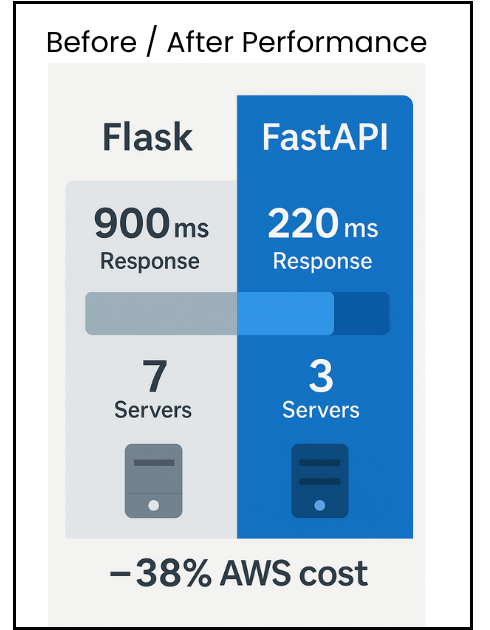
Case Study: Real-Time SaaS Dashboard
A US SaaS firm needed real-time metrics for thousands of IoT devices. We rebuilt its backend with FastAPI + async WebSockets on AWS Fargate. Results: average response time 840 ms → 190 ms, server count 7 → 3, monthly AWS cost −38 percent.
Security and Compliance: The Backbone of Trust
Speed is impressive only when paired with security. FastAPI offers OAuth2 and JWT support, but implementation defines safety. We embed compliance at code level through dependency-based access control, CORS middleware, and encrypted environment keys.
from fastapi import Depends, Security
from fastapi.security import OAuth2PasswordBearer
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/user/me")
async def read_users_me(token: str = Security(oauth2_scheme)):
return verify_token(token)
Our builds are GDPR- and SOC 2-ready, and healthcare clients rely on them for HIPAA validation.
Performance Optimization Playbook
When founders ask how to reach sub-250 ms latency without breaking the bank, our answer is simple: pair FastAPI with pragmatic engineering. Below is the high-impact, low-risk playbook we apply on every build.
Optimize the Data Layer First
Slow queries destroy great APIs. We standardize async patterns and lean indexes so your Python APIs return fast under real traffic, not just in local tests.
- Async I/O: Prefer async drivers and connection pooling to reduce queue time.
- Query shape: Return only what the client needs; paginate everything by default.
- Hot paths: Cache high-frequency reads with Redis and short, rolling TTLs.
For deeper guidance, see our service page on FastAPI development services where we outline patterns for multi-tenant SaaS and real-time feeds.
Cut Payload and Network Overhead
Bandwidth is latency. Trim what you ship to the browser or mobile client without changing your domain logic.
- Compression: Enable gzip and brotli at the edge to shrink responses noticeably.
- Selective fields: Shape responses with whitelists; avoid returning entire models.
- Idempotent GETs: Make them cacheable with ETags and sensible Cache-Control headers.
Background Work Belongs in Queues
Don’t make users wait for long operations. Offload enrichment, email, or post-processing to workers while the API stays snappy.
- Task queues: Use lightweight workers for image, doc, and ML preprocessing.
- Circuit breakers: Fail fast on unstable upstreams; degrade gracefully.
- Observability: Track queue depth, execution time, and retries to prevent drift.
Measure What Matters
Dashboards beat hunches. We expose RED metrics (rate, errors, duration) for every route and alert on realistic SLOs so teams react before customers complain.
Want a practical, code-level walk-through? Our team built end-to-end AI workflows documented in AI Workflows with FastAPI and LangGraph, including request orchestration and guardrails.
AI and LLM Integrations with FastAPI
Modern products are intelligent by default. FastAPI is a natural fit for LLM routing, embeddings, and streaming inference thanks to async concurrency and clean dependency injection.
Patterns We Use in Production
- LLM gateways: Route traffic to multiple providers with fallbacks and cost caps.
- Hybrid retrieval: Combine vector search with relational filters for relevance and governance.
- Streaming endpoints: Deliver partial results for perceptual speed on long tasks.
See a concrete consumer-facing example in our build notes: AI Kitchen Planner with OpenAI, Weaviate, and FastAPI. The same patterns apply to fintech, healthtech, and B2B SaaS.
Security and Compliance for AI APIs
Intelligent endpoints still need enterprise hygiene. We implement role-based access via dependencies, key rotation, and content filters before persistence so you stay audit-ready. For healthcare workloads, our HIPAA-compliant AI hospital system shows how to align privacy with ML utility.
For async fundamentals and back-pressure strategies, the official Python AsyncIO documentation is a reliable reference.
Cost and ROI: Faster APIs, Smaller Cloud Bills
Performance without efficiency is a vanity metric. The right FastAPI architecture lowers total cost while improving customer experience.
- Concurrency wins: Handle more requests per pod, delay horizontal scale, and cut idle compute.
- Hot path caching: Cache once, serve thousands; especially for read-heavy dashboards.
- Autoscaling: Scale on queue depth and P95 latency, not just CPU.
In our social automation engagement, we paired caching and burst control to reduce spend significantly; the approach is summarized in the AI content automation case study.
Deployment that Doesn’t Flinch
Uptime is a product feature. We ship predictable pipelines so "deploy" and "relax" can exist in the same sentence.
- Containers: Multi-stage builds with reproducible artifacts.
- Process model: Uvicorn workers behind Gunicorn for balanced concurrency.
- Edge: NGINX for rate limiting, caching, and request normalization.
- Orchestration: EKS, GKE, or AKS with HPA tuned to P95 latency.
- CI/CD: GitHub Actions or Jenkins with canary and auto-rollback.
If you want a side-by-side performance perspective, consult the independent TechEmpower benchmarks while mapping to your traffic model.
Hiring Models that Match Your Roadmap
No two teams scale the same way. We align delivery to your constraints so you move quickly and stay in control.
Dedicated FastAPI Developers
Embedded engineers who adopt your rituals and toolchain. Best for long-running SaaS platforms and feature velocity.
Project-Based Delivery
Clear scope, fixed milestones, predictable cost. Ideal for MVPs, migrations, and time-boxed integrations.
Retainer and Reliability Engineering
Post-launch improvements, versioning, load tests, and on-call rotation. Your uptime graph becomes boring—in the best way.
Compare models and outcomes on our FastAPI development services page; we include sample timelines and acceptance criteria.
CTO Readiness Checklist
Before you pick a partner, align the non-negotiables. A disciplined vendor should check every box below.
- Proven work: Delivered high-traffic Python APIs with clean rollouts.
- Async fluency: Can explain event loops, back-pressure, and safe cancellation.
- DevOps maturity: Uses metrics to drive capacity, not guesswork.
- Compliance muscle: Understands GDPR, HIPAA, and data residency.
- Post-launch plan: Versioning, SLOs, and incident response defined up front.
Client Story (Condensed)
"We had traction but slipped during spikes. Zestminds re-platformed our API in FastAPI with queues and caching. Today we handle millions of daily calls with headroom to spare." - CEO, US FinTech

Frequently Asked Questions
Is FastAPI better than Flask or Django for startups?
For API-centric products, yes. FastAPI provides async performance, type validation, and auto-docs that speed delivery without painting you into a corner.
How scalable is FastAPI for enterprise systems?
With Uvicorn workers and Kubernetes autoscaling, FastAPI handles thousands of requests per second per node. The key is disciplined observability and caching.
Can FastAPI integrate with LLMs and vector databases?
Absolutely. We routinely combine embeddings, retrieval, and streaming completions. A public example is our AI kitchen planner using OpenAI and Weaviate.
How fast can we get an MVP live?
Typical MVPs land in weeks, not months, thanks to typed models and generated OpenAPI docs. See our approaches on the service page.
What about security and audits?
We implement OAuth2, JWT rotation, and encrypted configuration. For privacy-critical workloads, review our HIPAA-compliant system case study to understand our audit approach.
Architect Your FastAPI Roadmap
If your 90-day goals include faster responses, cleaner deployments, and lower spend, we should talk. Our architects will review your current stack and design a pragmatic, staged adoption plan.
- Deliverables: Architecture diagram, SLO targets, migration plan.
- Scope: One discovery call plus a written summary you can share internally.
- Next step: Book a slot and tell us your top three constraints.
Start here: Book a FastAPI consultation with Zestminds. For AI-heavy roadmaps, skim our applied guides on AI workflows with FastAPI and the AsyncIO runtime.
Conclusion
FastAPI turns Python into a performance platform without losing developer joy. Pair it with disciplined architecture and you get a system that is fast today and still easy to evolve a year from now. If you want the shortest path from idea to resilient production, we are ready to help.
Further Reading
For independent performance context, review the latest TechEmpower benchmarks. For framework specifics and patterns, the canonical FastAPI documentation remains the definitive reference.
Rajat Sharma
About the Author
With over 8 years of experience in software development, I am an Experienced Software Engineer with a demonstrated history of working in the information technology and services industry. Skilled in Python (Programming Language), PHP, jQuery, Ruby on Rails, and CakePHP.. I lead a team of skilled engineers, helping businesses streamline processes, optimize performance, and achieve growth through scalable web and mobile applications, AI integration, and automation.
Stay Ahead with Expert Insights & Trends
Explore industry trends, expert analysis, and actionable strategies to drive success in AI, software development, and digital transformation.


