Common Backend Scaling Mistakes We See in Growing Products
Backend scaling rarely fails with a loud crash. It fails quietly.
Things feel "mostly fine," but deploys slow down, dashboards feel noisy, and fixes take longer than they should.
Latency creeps in, incidents repeat, and confidence drops, long before traffic explodes.
This article walks through the backend scaling mistakes we consistently see in growing products, and how experienced teams spot them early.

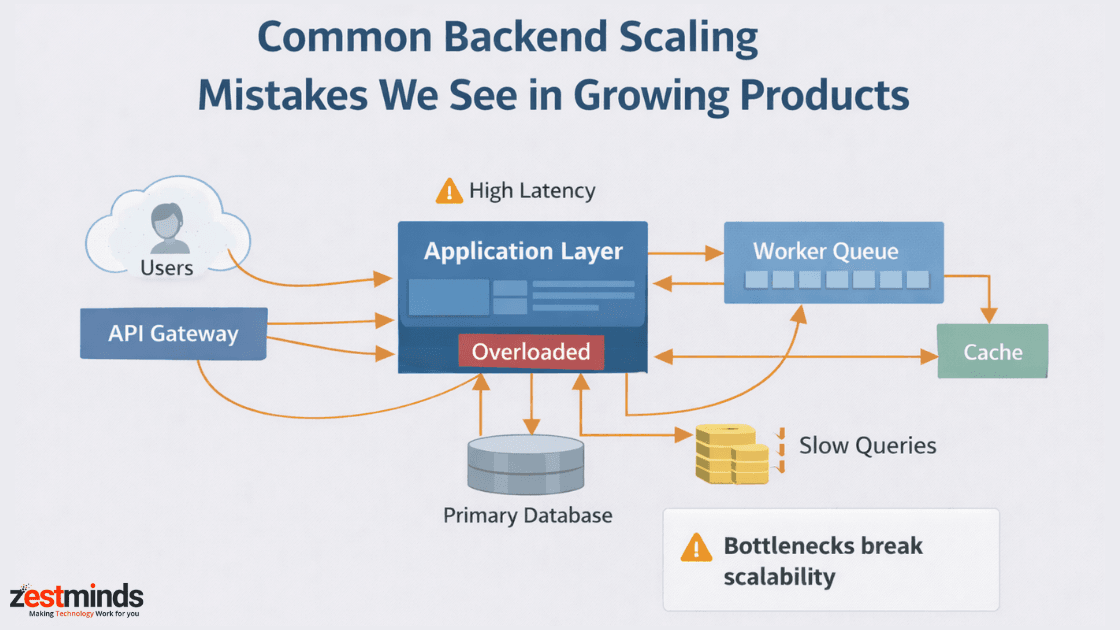
Scaling Isn't About Traffic, It's About Load Patterns
Most teams equate scaling with "more users."
In practice, many backend scaling mistakes happen because pain comes from how users behave, not how many there are, especially when you factor in how real-world load patterns and latency affect system performance rather than raw traffic volume.
A product with 10k users can be harder to scale than one with 1M if usage is bursty, stateful, or tightly synchronized.
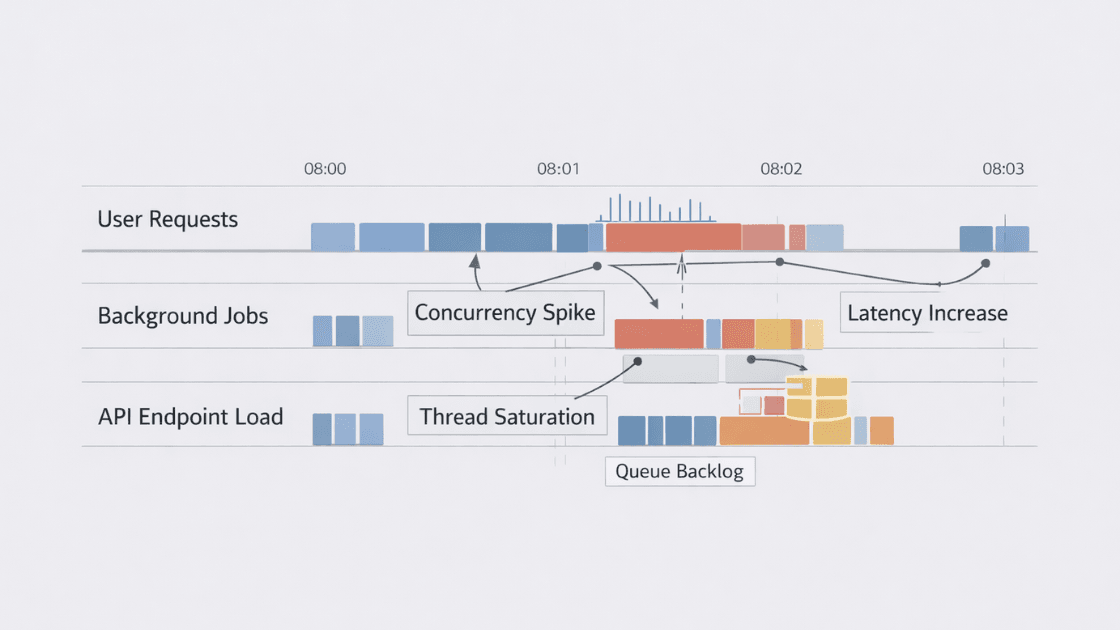
We've seen systems stumble not during steady growth, but when:
- A background job overlaps with peak traffic
- One endpoint suddenly gets hit concurrently
- A "quick" admin export runs at the wrong hour
Nothing new was added. The system just met reality, often because of early architectural assumptions that quietly stop scaling.
The common mistake
Designing for average traffic instead of worst-case concurrency.
Early on, everything behaves politely:
- Requests line up
- Databases respond instantly
- APIs feel fast enough
Then concurrency increases, and the politeness disappears.
Why it breaks
- Synchronous calls stack up
- Connection pools saturate
- Threads block on I/O
- Latency multiplies across layers
The backend didn't suddenly become slow. It became contested.
What experienced teams do differently
They think in load shapes, not counts:
- Where do spikes come from?
- What blocks under pressure?
- What can queue safely?
- What must respond immediately?
If you can't answer those, scaling becomes reactive by default.
Database Decisions That Quietly Kill Scalability
If there's one pattern we see again and again, it's this: the database becomes the bottleneck before anyone expects it.
Not because databases are fragile, but because teams lean on them too hard.
The common mistake
Using the database as:
- A message queue
- A cache
- A session store
- A reporting engine
All at once.
Early-stage products usually start with a single primary database. It's simple, familiar, and productive. Until growth turns that convenience into contention.
What we typically see
- One table doing five different jobs
- Queries added organically with no performance budget
- Indexes that made sense a year ago
- Reads and writes fighting under load
| Usage Pattern | Works at Low Scale | Fails at Growth | Primary Risk |
|---|---|---|---|
| Single DB for all workloads | Yes | Yes | Lock contention |
| DB as cache | Yes | Yes | Latency spikes |
| DB-backed queues | Sometimes | Often | Backpressure collapse |
| Mixed OLTP + reporting | Yes | No | Query starvation |
A simple analogy
Think of your database like a home kitchen fridge.
At home, one fridge is fine. In a restaurant, it becomes chaos.
Same fridge. Very different usage.
How teams get stuck
They optimize queries one by one, without stepping back to ask:
- Which reads should never hit the database?
- Which writes don't need to be synchronous?
- Which workloads should be isolated?
By the time those questions surface, pressure is already on.
Before teams jump to architectural changes, this is often the moment to pause and diagnose whether the problem is structural, or simply misplaced responsibility.
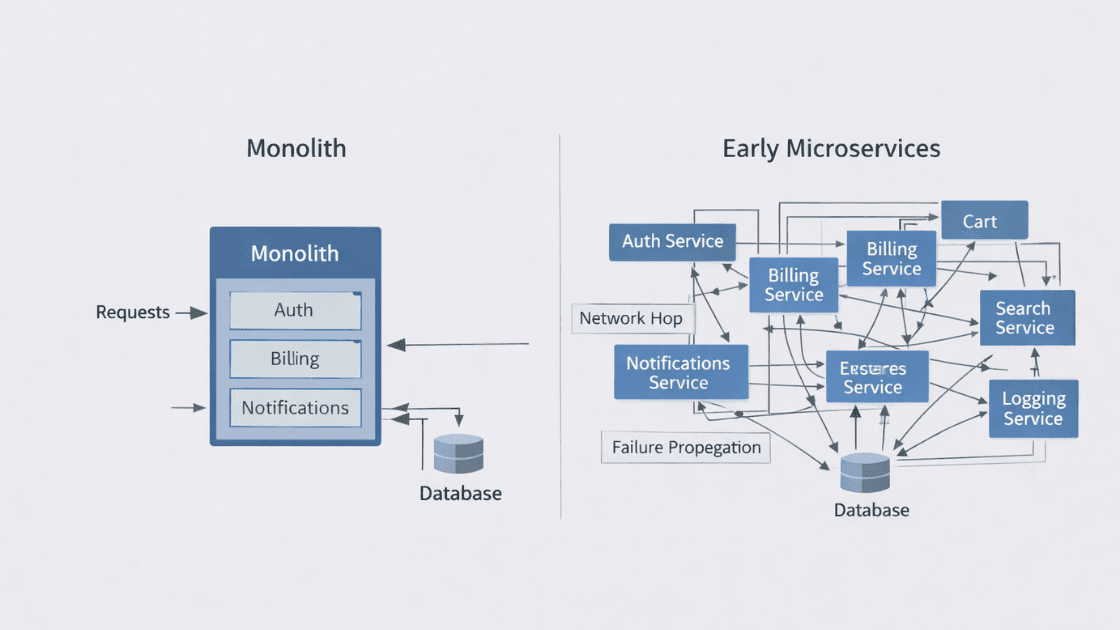
Over-Engineering Too Early (and Under-Engineering the Right Parts)
This mistake shows up in two opposite, and equally costly, forms.
Form 1: Microservices too early
Teams split a working monolith because:
- "That's how scaling works"
- "We'll need this later anyway"
- "It feels more future-proof"
What they get instead:
- Network latency replacing function calls
- Distributed failures
- Complex deployments
- Harder debugging
All before product-market fit is clear.
Form 2: Weak foundations where it matters most
At the same time, critical paths often lack:
- Idempotency
- Retries
- Rate limiting
- Clear failure handling
So the system is complex where it shouldn't be, and fragile where it must be strong.
The real scaling insight
Scalability isn't about having more services. It's about clear boundaries and predictable failure modes.
Many CTOs eventually learn this the hard way: a well-structured monolith often scales better than a poorly designed distributed system, especially when teams focus on modernizing backend systems without burning everything down instead of defaulting to a rewrite.
The real question isn't, "Should we use microservices?" It's, "Where do we need isolation, and where do we need simplicity?"
Stateless Backends on Paper, Stateful in Reality
Ask a team whether their backend is stateless.
Most will say yes. The code even looks stateless.
Then horizontal scaling starts, and strange things happen.
The hidden state problem
State sneaks in through:
- In-memory sessions
- Local file storage
- Cached assumptions
- Long-running background tasks
Everything works on one instance. On three, edge cases appear. On ten, behavior becomes unpredictable.
A familiar scenario
Authentication works perfectly, until a load balancer is added.
Why?
- Session data lives in memory
- Requests bounce between instances
- Users randomly log out
The backend wasn't stateless. It was accidentally stateful.
- Session in memory
- Load balancer added
- Request hops
- Session lost
- Sticky sessions
- Scaling capped
Why this blocks scaling
Horizontal scaling assumes any request can hit any instance.
Hidden state breaks that assumption.
Teams then reach for:
- Sticky sessions
- Instance pinning
- Manual routing rules
These fix symptoms, but quietly cap scalability.
What scalable systems do
They treat state as a first-class design concern:
- Externalize it
- Version it
- Control its lifecycle
Statelessness isn't a checkbox. It's a habit.
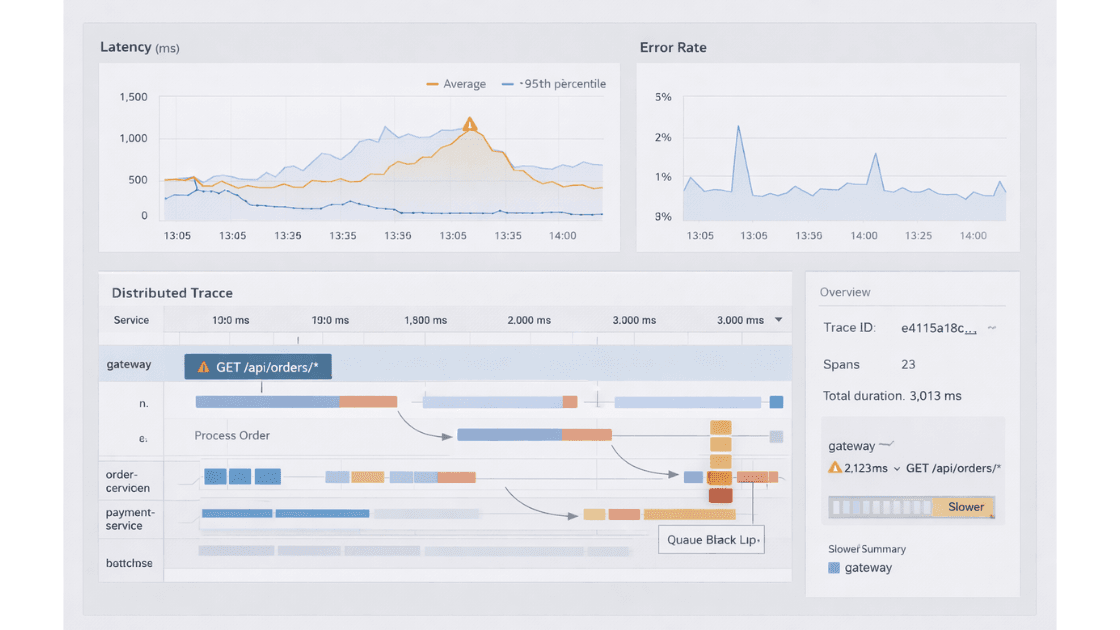
Ignoring Observability Until It's Already Too Late
Most teams invest in observability after something breaks.
By then, they're debugging in the dark, often during an incident where answers are needed immediately.
The common mistake
Relying on:
- Basic logs
- A few metrics
- Manual reproduction
This works when systems are small and linear.
It fails once:
- Requests span multiple services
- Latency compounds
- Failures cascade
What "too late" looks like
You'll hear questions like:
- "Is the API slow or the database?"
- "Which endpoint is actually causing load?"
- "Why does this only happen in production?"
And no one can answer confidently, something many teams only realize after seeing it play out in production.
Why observability matters for scaling
Scaling introduces unknown interactions, which is why experienced teams rely on foundational observability practices for measuring system health at scale rather than ad-hoc logging.
Observability lets you:
- See where time is spent
- Identify saturation early
- Catch regressions before users do
Without it, teams guess. Guessing doesn't scale.
The mindset shift
Observability isn't just for debugging. It's part of system design.
If you can't see it clearly, you can't scale it safely.
Scaling the Backend Without Scaling the Team's Mental Model
This is the most underestimated mistake, and often the most damaging.
Systems grow. Understanding doesn't always keep up.
What we often observe
- One engineer holds critical knowledge
- Deployments feel increasingly risky
- Small changes take too long
- Incidents repeat with familiar patterns
- Single knowledge holder
- Risky deploys
- Repeated incidents
- Outdated diagrams
- Tribal knowledge
Technically, the system scales. Cognitively, it doesn't.
Why this matters
A backend isn't just code. It's a shared mental model.
When that model lives in:
- One person's head
- Outdated diagrams
- Tribal knowledge
The system becomes fragile, no matter how good the infrastructure is.
Scaling failure isn't always technical
Many CTOs share a common lesson: some of the worst incidents aren't caused by traffic, but by misunderstood assumptions.
Misuse, confusion, and fear-driven decisions scale faster than bugs.
What strong teams do
They invest in:
- Clear boundaries
- Explicit contracts
- Simple explanations
- Shared ownership
Because real scalability includes people.
Where This Usually Leaves Growing Teams
By the time these patterns become obvious, teams are often dealing with:
- Slower feature delivery
- Increasing incident frequency
- Pressure to "rewrite everything"
| Option | Short-Term Relief | Long-Term Risk | When It Makes Sense |
|---|---|---|---|
| Full rewrite | Emotional relief | Very high | Rarely |
| Add infrastructure | Temporary | Medium | When load is misdiagnosed |
| Targeted refactor | Moderate | Low | Most cases |
| System audit | High | Lowest | Before major change |
In many cases, a full rewrite isn't necessary.
What is necessary is a clear, honest assessment of:
- What's truly limiting scale
- Which decisions are reversible
- Where targeted fixes unlock the most headroom
That's usually the moment teams move from diagnosing problems to choosing a path forward, often facing the rewrite-versus-refactor decision most CTOs eventually face, and why a grounded comparison is often far more valuable than adding more infrastructure or starting from scratch.
Frequently asked question
What are the most common backend scaling mistakes in growing products?
The most common backend scaling mistakes include designing for average traffic instead of peak concurrency, overloading the database with multiple responsibilities, introducing microservices too early, hidden state in supposedly stateless systems, and delaying observability until incidents occur. These issues usually surface quietly as latency, instability, and slower development velocity.
Why do backend systems struggle even when user growth is moderate?
Backend systems often struggle due to load patterns rather than user count. Bursty traffic, background jobs overlapping with peak usage, and concurrent requests can overwhelm databases and application layers even at relatively low user numbers.
How do databases become scaling bottlenecks over time?
Databases become bottlenecks when they are used simultaneously for transactional workloads, caching, queues, sessions, and reporting. As data volume and concurrency increase, lock contention, slow queries, and resource starvation quietly degrade system performance.
Is rewriting the backend the best solution for scaling problems?
In most cases, a full backend rewrite is not necessary. Targeted refactoring, better workload isolation, improved observability, and architectural clarity often resolve scaling issues more effectively and with significantly lower risk than a complete rewrite.
Why is observability critical for backend scalability?
Observability allows teams to understand where time is spent, how requests flow through the system, and where bottlenecks emerge under load. Without proper observability, teams rely on assumptions, making backend scaling decisions reactive and error-prone.
How does team knowledge affect backend scalability?
Backend scalability is not only a technical challenge but also an organizational one. When system understanding lives in a few individuals or outdated documentation, deployments become risky, incidents repeat, and scaling efforts slow down regardless of infrastructure improvements.
Table of Contents
- Scaling Isn't About Traffic, It's About Load Patterns
- Database Decisions That Quietly Kill Scalability
- Over-Engineering Too Early (and Under-Engineering the Right Parts)
- Stateless Backends on Paper, Stateful in Reality
- Ignoring Observability Until It's Already Too Late
- Scaling the Backend Without Scaling the Team's Mental Model
- Where This Usually Leaves Growing Teams
- Frequently Asked Questions
Shivam Sharma
Before You Scale Further, Review the Architecture.
Let’s evaluate where your system stands — and where it may break under growth.
Schedule an Architecture Review 30-minute technical discussion. No obligation.
