Rewrite vs Refactor: How CTOs Make the Right Call at Scale
Rewrite vs refactor isn't a technical argument.
It's a capital, risk, and focus decision that quietly shapes your next 2-3 years.
The right choice depends less on code quality, and more on where your business is actually going.

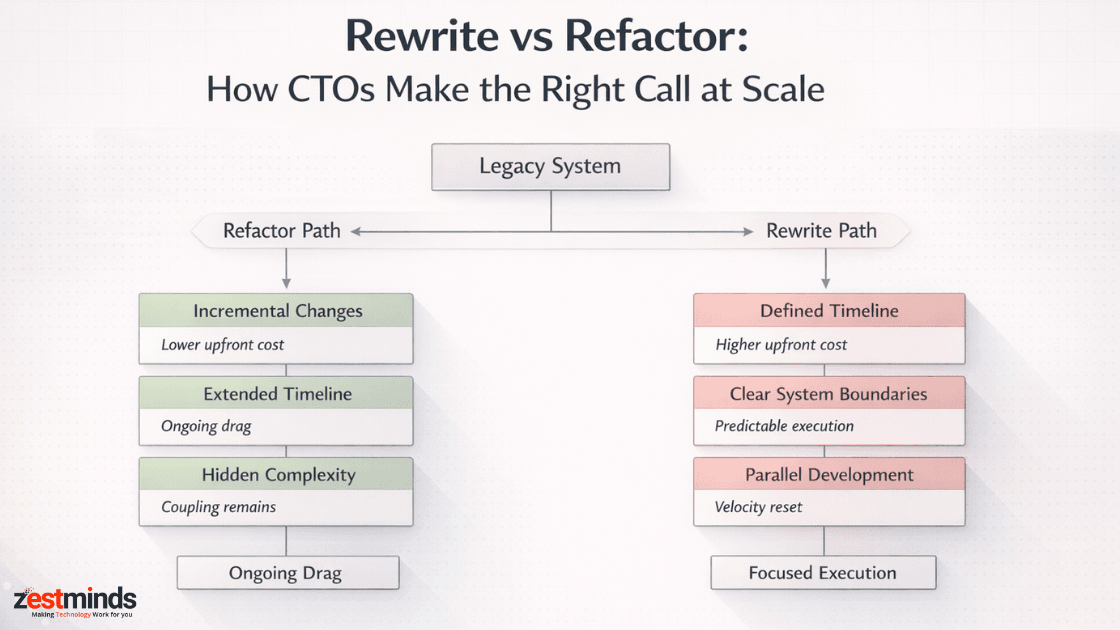
Rewrite vs refactor is not a technical decision. CTOs should refactor when the architecture still fits business goals, and rewrite when growth, scale, or team velocity is structurally blocked.
Why "Rewrite vs Refactor" Is a Business Decision
Most CTOs first approach rewrite vs refactor as a technical debate.
That's understandable, and usually where things start going wrong, because architecture decisions made early often come back to haunt teams (https://www.zestminds.com/blog/mvp-architecture-breaks-6-12-months/) as products scale beyond their original assumptions.
At scale-up stage, your codebase stops being "just software."
It becomes operational infrastructure for growth.
Every significant change now competes with:
- Roadmap commitments
- Customer expectations
- Hiring and onboarding plans
- Revenue and runway realities
Refactoring feels responsible.
Rewriting feels dangerous.
But many CTOs quietly discover something uncomfortable:
the most expensive path is staying indecisive.
If your system:
- Slows feature delivery month after month
- Requires one or two "only they understand it" engineers
- Breaks in ways no one can fully explain
- Forces workarounds instead of clean solutions
Then you're already paying rewrite-level costs, often over 12-24 months of incremental refactors that still don't change the trajectory.
This decision matters because it affects:
- How fast you can respond to market pressure
- Whether senior engineers stay motivated
- How easily you can scale teams in parallel
- Your long-term cost of ownership
At this point, the real question isn't "Which option is cleaner?"
It's "Which option gives us leverage over the next 24-36 months?"
Decision Pressure Signals
- Roadmap slipping despite "cleanup" efforts
- Senior engineers acting as gatekeepers
- Features scoped down to avoid risky areas
- Architecture debates blocking product discussions
The True Cost Breakdown: Refactor vs Rewrite
Most discussions underestimate cost because they focus only on engineering effort.
That's a narrow and risky view, especially when we've seen this play out in real legacy modernization projects (https://www.zestminds.com/legacy-system-modernization-without-rewrite-case-study) where refactoring quietly extended timelines instead of reducing them.
Cost Reality: Refactor vs Rewrite
| Dimension | Refactor Path | Rewrite Path |
|---|---|---|
| Initial cost | Lower upfront, appears safer | Higher upfront, clearly visible |
| Timeline predictability | Low (scope creep, hybrid state) | Medium-High (bounded plan) |
| Parallel development | Difficult (shared constraints) | Planned (dual-run possible) |
| Cognitive load | Rises (mixed patterns) | Drops after cutover |
| Long-term velocity | Often stagnates | Resets upward post-transition |
| Risk type | Slow bleed (opportunity cost) | Execution spike (manageable) |
At scale, refactoring often stretches to 12-24 months with limited ROI, while a well-scoped rewrite is typically a defined 6-12 month effort with predictable outcomes.
Refactoring: The Cost You Don't See on the Spreadsheet
Refactoring is often described as "low risk" because production keeps running.
In reality, refactoring at scale creates ongoing drag.
You end up paying for:
- Engineers juggling old and new patterns at the same time
- Higher cognitive load across the team
- Slower onboarding because nothing feels consistent
- Extra testing to protect half-modernized workflows
A familiar pattern we see:
- Refactor starts with good intentions
- Scope is kept "safe and small"
- Six months later, only part of the system is better
- Velocity drops because the codebase is now hybrid
Refactoring stops being cheaper when:
- There's no clear end state
- Technical debt is stretched, not removed
- Future architecture decisions remain blocked
In practice, this often means 6-18 months of effort with limited ROI, followed by the same rewrite discussion resurfacing.
Rewriting: Expensive, Yes, But Predictable
Rewrites have a bad reputation, and for good reason.
Poorly planned rewrites fail loudly.
But the fear is often misplaced.
The real cost drivers of a rewrite are:
- Unclear system boundaries
- No parallel rollout strategy
- Rebuilding features users no longer care about
- Freezing product development unnecessarily
When those mistakes are avoided, rewrites behave very differently.
A well-scoped rewrite:
- Targets only what blocks growth
- Preserves proven business logic
- Improves developer velocity soon after launch
- Lowers operational risk long-term
A practical way to think about it:
Rewrites are expensive upfront, often a defined 6–12 month investment, but bounded. Endless refactors are cheaper early and compound quietly.
Clear Signals That Refactoring Will Fail
Not every legacy system needs a rewrite.
But some signals are hard to ignore.
Signal 1: Your Architecture No Longer Matches the Business
If your product evolved from:
- MVP to multi-tenant SaaS
- One region to global users
- Simple workflows to data-heavy or AI-driven flows
…and the architecture never evolved with it, refactoring becomes surface-level.
You can refactor syntax and structure.
You can't refactor your way out of the wrong foundational assumptions, especially when those assumptions conflict with foundational architecture assumptions that don't align with global scale or distributed systems, as outlined in modern cloud architecture best practices by Google Cloud (https://cloud.google.com/architecture).
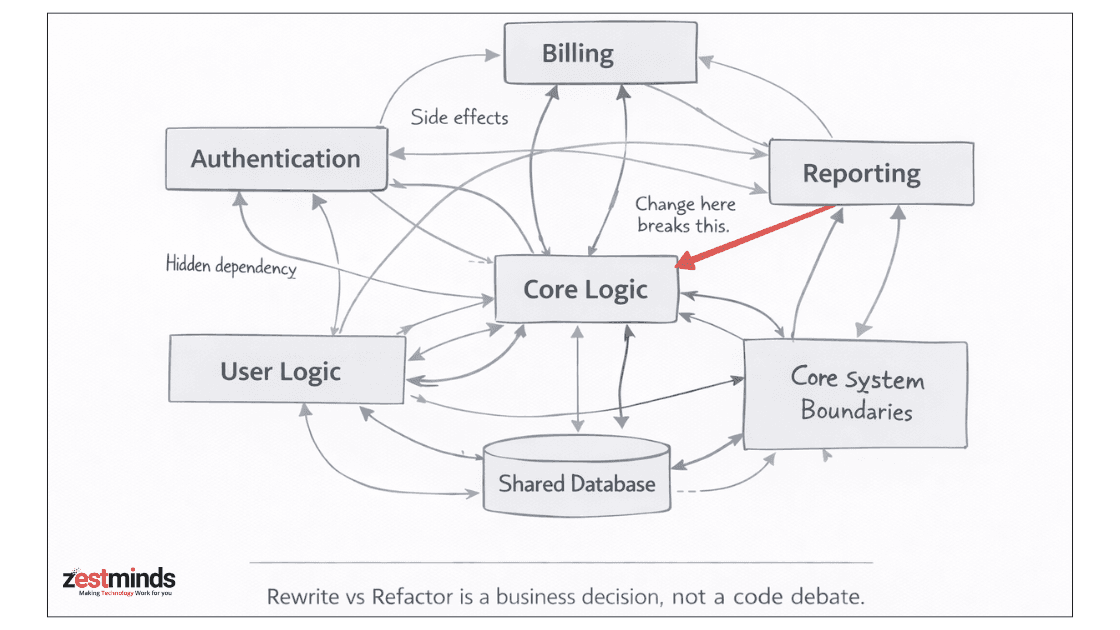
Signal 2: Change in One Area Breaks Three Others
When a small feature update triggers unexpected failures elsewhere, that's not messy code.
It's deep coupling baked into the system.
Refactoring works when:
- Boundaries exist but need cleanup
- Responsibilities are mostly clear
It fails when:
- Logic is scattered across layers
- Side effects are undocumented
- Tests describe outcomes but not intent
At that point, refactoring treats symptoms, not causes.
Signal 3: Velocity Drops Even With Senior Engineers
This one is expensive and easy to miss.
If you've hired capable engineers but notice:
- PRs taking longer over time
- Teams avoiding "that part" of the system
- Fear-driven development becoming normal
Then the system not the people is the bottleneck.
A common CTO mistake here is assuming this is a people or process issue, when it's actually architectural.
Experienced CTOs often note this is the moment refactoring stops being a fix.
When a Rewrite Actually Makes Sense (And When It Doesn't)
Rewriting isn't bold leadership by default.
It's only the right move under the right conditions.
Rewrite vs Refactor: Decision Boundaries
| Decision Condition | Refactor, When It Makes Sense | Rewrite, When It Makes Sense |
|---|---|---|
| Product direction still shifting weekly | Safer option while requirements are unstable | High risk, likely to rebuild the wrong thing |
| Architecture blocks critical roadmap items | Temporary relief at best, constraints remain | Recommended to unlock growth and delivery |
| Core domain logic not well understood | Not ideal, refactors lack clear intent | Not recommended, clarify domain first |
| Clear system boundaries can be defined | Possible, but hybrid complexity often increases | Strong candidate for a controlled rewrite |
| Multiple teams must ship in parallel | Hard to scale safely with shared constraints | Enables parallel velocity and ownership |
Rewrite Makes Sense When:
- Critical roadmap items are blocked by architecture
- Scaling requires structural changes, not optimizations
- Technical debt is foundational, not cosmetic
- You need parallel team velocity, not heroic effort
- Clear system boundaries can be defined
In these cases, a rewrite becomes an investment in future flexibility.
Rewrite Does Not Make Sense When:
- The product direction is still unstable
- Requirements change weekly
- Core business logic isn't well understood
- There's little test coverage or domain clarity
- Leadership expects "same system, just cleaner"
If you're still validating the product or business model, a rewrite is almost always premature.
Rewriting a moving target almost always fails.
In practice, many successful teams choose selective rewrites:
- Rebuild the core that limits scale
- Keep stable edges intact
- Migrate gradually with tight control
This approach sounds obvious, but executing it well is where experience matters.
A CTO Decision Framework We Use in Real Projects
When we work with CTOs, we don't ask, "Rewrite or refactor?"
We ask a different set of questions, because the kind of technical partner you involve at this stage matters (https://www.zestminds.com/blog/choose-software-development-partner-2026/) as much as the decision itself.
Rewrite vs Refactor Evaluation
- What business capability is blocked today?
- Which system/module owns that capability?
- Can it be isolated safely behind stable interfaces?
- What breaks if you do nothing for 12 months?
- What does "success" look like operationally?
1. What Must Change in the Next 18 Months?
Not what's broken today, but what's coming:
- New markets
- New pricing or usage models
- Higher data volume
- Compliance or reliability expectations
If the system can't support these without heavy workarounds, refactoring is delay, not strategy.
2. Where Is Complexity Actually Concentrated?
Legacy systems are rarely bad everywhere.
We map:
- High-change areas
- High-risk workflows
- High-coupling modules
Often, a small portion of the system causes most of the pain, and points directly to where rewriting matters.
3. Can You Isolate Before You Rewrite?
Safe rewrites require isolation.
That means:
- Clear contracts
- Stable interfaces
- Ability to run old and new systems side by side
If isolation isn't possible yet, limited refactoring may be necessary, but only as a step toward rewriting.
4. What Does "Success" Look Like After the Decision?
Many teams never define this.
Success should be measurable:
- Deployment frequency
- Time to ship new features
- Mean time to recovery
- Onboarding speed for new engineers
Without this clarity, both refactors and rewrites drift.
5. Which Risk Can the Business Absorb?
Every option carries risk.
Refactoring carries opportunity cost and schedule risk.
Rewriting carries execution risk.
The right choice depends on which risk your business can survive.
The biggest risk in rewriting is not cost, it is rebuilding without clear system boundaries or stable requirements.
How to Reduce Risk If You Must Rewrite
Most rewrite failures are strategic, not technical.
Here's what experienced teams do differently.
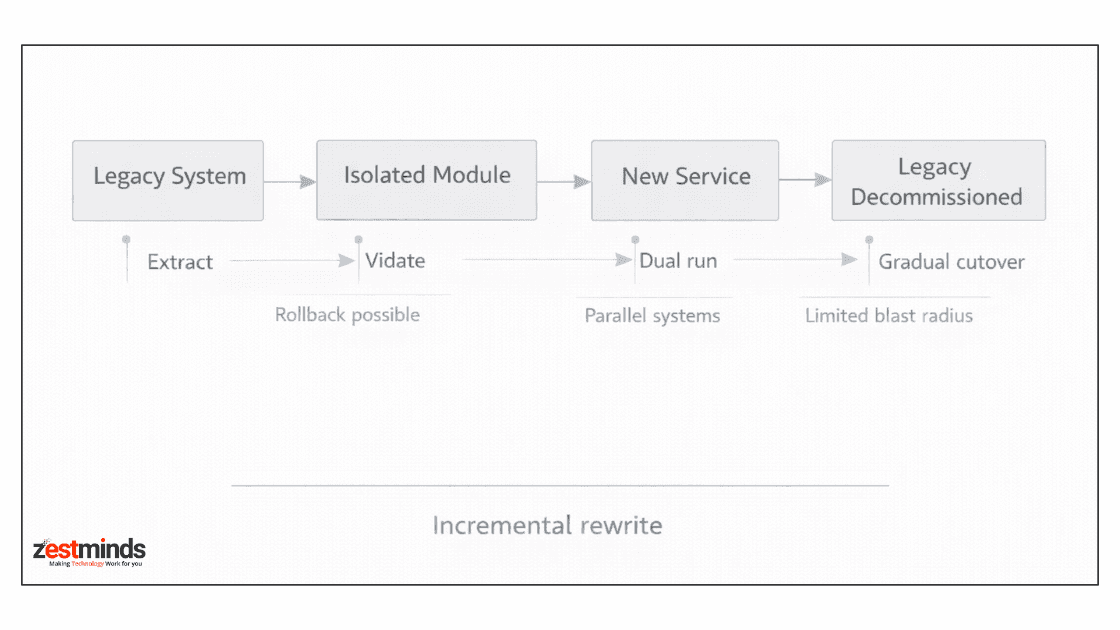
Rewrite in Thin Vertical Slices
Avoid "platform-first" thinking.
Instead:
- Pick one critical workflow
- Rebuild it end to end
- Validate in production
- Expand gradually
This aligns with incremental modernization approaches that emphasize isolation and parallel systems, as detailed in AWS prescriptive guidance on application modernization (https://docs.aws.amazon.com/prescriptive-guidance/latest/application-modernization/introduction.html).
Keep Product Momentum Alive
A rewrite shouldn't freeze innovation.
If development pauses for a year:
- The market moves
- Customers lose patience
- Pressure rises
- Corners get cut
Parallel progress is difficult, but necessary.
Preserve Business Logic, Not Code
Many CTOs learn this lesson late.
Document:
- Why rules exist
- Which constraints matter
- Which edge cases were learned the hard way
Code can be replaced.
Hard-earned domain knowledge cannot.
Plan the Exit From Day One
Decide early:
- When old systems retire
- What metrics trigger cutover
- How rollback works
Without an exit plan, teams run two systems too long, and pay twice.
One Practical Takeaway for CTOs
If there's one idea worth carrying forward, it's this:
Refactoring optimizes the present. Rewriting enables the future.
In short:
- Refactor when the architecture still fits the business.
- Rewrite when the business has outgrown the architecture.
Avoiding the decision, however, is almost always the most expensive choice.
If you're weighing a rewrite vs refactor decision and want a grounded, architecture-level assessment, covering cost range, timeline, and execution risk, this is exactly the type of evaluation we help CTOs with, focused on business impact rather than theory.
Frequently Asked Question
Is it always better to rewrite than refactor at scale?
No. A rewrite is only justified when the existing architecture actively blocks business growth. If the core system still aligns with the product direction and can support upcoming changes, refactoring can be the smarter, lower-risk choice.
How long does a typical rewrite take compared to refactoring?
A well-scoped rewrite is usually a defined effort often 6–12 months for critical systems. Refactoring may appear shorter, but at scale it often stretches to 12–24 months without fully removing the underlying constraints.
Can we refactor first and rewrite later?
Yes, but only if refactoring is used deliberately to isolate boundaries or reduce risk before a rewrite. Refactoring without a clear end goal often delays the rewrite decision while increasing complexity.
What is the biggest risk of rewriting a legacy system?
The biggest risk is rebuilding without clear system boundaries or stable requirements. Rewrites fail when teams attempt to recreate everything at once or freeze product development instead of running systems in parallel.
How do CTOs know when refactoring has stopped working?
Common signals include declining delivery speed despite senior engineers, fear-driven development around certain modules, and repeated incidents where small changes cause widespread failures.
Does rewriting mean throwing away all existing code?
No. Successful rewrites preserve business logic and domain knowledge. The goal is to replace the structure and constraints, not the hard-earned rules that make the business work.
Who should be involved in a rewrite vs refactor decision?
Beyond engineering leadership, product, operations, and business stakeholders should be involved. This decision impacts timelines, revenue, hiring, and customer experience, not just code quality.
Table of Contents
- Why "Rewrite vs Refactor" Is a Business Decision
- The True Cost Breakdown: Refactor vs Rewrite
- Clear Signals That Refactoring Will Fail
- When a Rewrite Actually Makes Sense (And When It Doesn't)
- A CTO Decision Framework We Use in Real Projects
- How to Reduce Risk If You Must Rewrite
- One Practical Takeaway for CTOs
- FAQs
Shivam Sharma
Before You Scale Further, Review the Architecture.
Let’s evaluate where your system stands — and where it may break under growth.
Schedule an Architecture Review 30-minute technical discussion. No obligation.
